Scalable and Fast Read-Write Locks
Intro
Read-Write locks are a kind of concurrency construct that allows for multiple threads to access a resource or set of
resources concurrently. What this means in practice is, if you have an object or set of objects that you want to access mostly in read-only access then it is worth considering protecting them with a Read-Write lock, henceforth named RWLock.
Java provides a very good RWLock created by Doug Lea in
java.util.concurrent.locks.ReentrantReadWriteLock, with lots of features like: Reentrancy, Fair-locking, Lock downgrading, etc.
And if you're a C developer stuck with PThreads, then you can use something like
pthread_rwlock_t and associated functions:
int pthread_rwlock_destroy(pthread_rwlock_t *);
int pthread_rwlock_init(pthread_rwlock_t *,
const pthread_rwlockattr_t *);
int pthread_rwlock_rdlock(pthread_rwlock_t *);
int pthread_rwlock_tryrdlock(pthread_rwlock_t *);
int pthread_rwlock_trywrlock(pthread_rwlock_t *);
int pthread_rwlock_unlock(pthread_rwlock_t *);
int pthread_rwlock_wrlock(pthread_rwlock_t *);
These also have a rich set of features like: Reentrancy and Priority Inheritance (not that you would want to open up that can of worms, but that's a topic for another post).
If you have a non-thread-safe data-structure that is mostly read and rarely written, protecting it with a RWLock is usually a good approach, or at least, better than using a simple Mutex. The rule of thumb for a
general data-structure (whatever
general means) is that 90% of the accesses are Reads, 9% are Inserts, and 1% are Deletes, thus giving more strength to the idea of using RWLocks.
It's all fun and games until someone gets hurt, namely whoever decides to use RWLocks on a high contention scenario. You see, most RWLock schemes use a variable that stores the number of threads currently doing a Read operation, which creates a lot of contention on a single variable. Let's call this variable
read_counter.
When the computation done between the lock() and unlock() is lengthy enough, compared to the locking mechanism itself, then the contention on the
read_counter is low and your application will not get a performance hit.
If instead, the code that is done between the lock() and unlock() is short, then you run the risk of getting high contention on the
read_counter, because you have multiple threads trying to write and read to a single cache line, namely, the one where the
read_counter is stored in memory.
If you think it is bad to have a single cache line being hammered by all the threads in a 4 core processor, just wait until your program gets to run on a 64 core processor, to see how much performance improvement you get.
I'm not a big fan of criticizing something unless we have an alternative to propose, therefore, the rest of this post will be a description of a scalable and fast RWLock, with some pretty plots in the end :)
If you don't want to waste time, then jump directly to the source code
ScalableRWLock.java
The Algorithm
Members definition
We start by defining an array of
readers_states where each entry is owned by a different thread that can do a Read operation, and we define a
write_state variable which will be shared by the threads attempting to do a Write operation.
private AtomicIntegerArray readers_states;
private char[] pad1;
private AtomicInteger write_state;
We add some
padding between the
readers_states and the
write_state to make sure that the last entries in the
readers_states array
will not share a cache line with the variable
write_state.
Each entry in
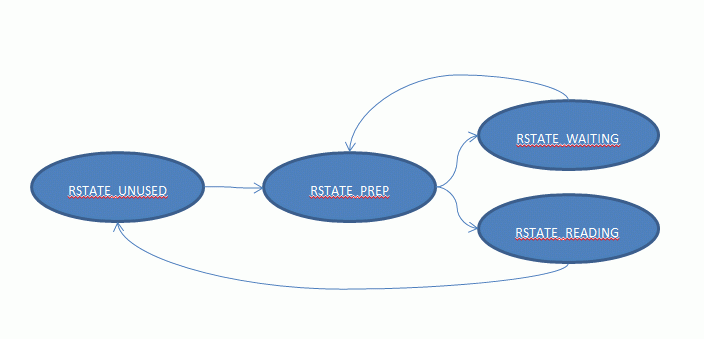
readers_states can be in one of the following states:
RSTATE_UNUSED: The thread owning this entry is not trying to access the resource protected by the RWLock.
RSTATE_PREP: The thread owning this entry is about to try to acquire the read-only lock.
RSTATE_WAITING: The thread has tried to acquire the read-only lock but saw that a thread doing a Write operation has acquire the lock in write-mode or is about to do so. The thread is most likely yielding/sleeping.
RSTATE_READING: The thread as acquire the lock in read-only mode and is currently accessing the resource which the RWLock guards.
private final int RSTATE_UNUSED = 0; // -> RSTATE_PREP
private final int RSTATE_WAITING = 1; // ->
RSTATE_PREP
private final int RSTATE_PREP = 2; // -> RSTATE_WAITING or ->
STATE_READING
private final int RSTATE_READING = 3; // ->
RSTATE_UNUSED
Notice that the numerical value of
RSTATE_PREP is larger than
RSTATE_WAITING and it is due to an optimization that we will see further in the code. Meanwhile, here is a diagram of the state machine for the Readers:
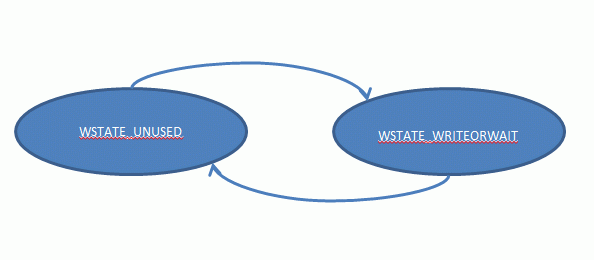
There is only one or no Writers accessing the lock at any given time, therefore, we need a single variable to store the state and there are only two states:
private final int WSTATE_UNUSED = 0; // -> WSTATE_WRITEORWAIT
private final int WSTATE_WRITEORWAIT =
1; // -> WSTATE_UNUSED
The
WSTATE_WRITEORWAIT means that one thread has the locked in write-mode, although it may still be scanning the
readers_states waiting for them to finish. The diagram of the state machine for the Writers is thus trivial:
Next, we need a thread-local variable
tid,
which will have the index corresponding to the entry of
readers_states that has been assigned to the current thread:
private transient final
ThreadLocal<Integer> tid;
private final ReentrantLock mutex;
private AtomicInteger num_assigned;
private long[] assigned_threads; //
Protected by mutex
Constructor
We can now write the constructor, starting with the allocation of the
readers_states as an array of size
MAX_NUM_THREADS*CACHE_PADD.The
CACHE_PADD multiplicative factor is used because we want to ensure that each entry has its own cache line. This implies we leave a lot of empty space, but there will be no contention at the cache line level between the threads doing Reads.
/**
* Default constructor.
*/
ScalableRWLock() {
//
States of the Readers, one per thread
readers_states = new AtomicIntegerArray(MAX_NUM_THREADS*CACHE_PADD);
for (int i = 0; i < MAX_NUM_THREADS*CACHE_PADD; i+=CACHE_PADD) {
readers_states.set(i, RSTATE_UNUSED);
}
pad1 = new char[CACHE_LINE];
pad1[3] = 42;
writer_state = new AtomicInteger(0);
//
This is AtomicInteger because it will be read outside of the mutex
num_assigned = new AtomicInteger(0);
assigned_threads = new long[MAX_NUM_THREADS];
for (int i = 0; i < MAX_NUM_THREADS; i++)
assigned_threads[i] = -1;
}
The entries in the assigned_threads array are initialized at -1 to mean they are free. They will later be filled by
threadInit() with the value returned from
Thread.currentThread().getId()
Initialization and cleanup for each thread
We create the function
threadInit() to find and allocate a free entry in
readers_states (and in
assigned_threads) and store the index of that entry in
tid.
Notice that the actual allocation of a free entry is done with a ReentrantLock guarding it, which is fine in terms of performance, because it is done only once per thread.
public void threadInit() {
if (num_assigned.get() >= MAX_NUM_THREADS) {
System.out.println("ERROR:
MAX_NUM_THREADS exceeded");
return;
}
mutex.lock();
for (int i = 0; i < MAX_NUM_THREADS; i++) {
if (assigned_threads[i] == -1) {
assigned_threads[i] = Thread.currentThread().getId();
tid.set(i);
num_assigned.incrementAndGet();
break;
}
}
mutex.unlock();
}
Notice that
num_assigned is incremented in an atomic way and with full memory barrier by using
incrementAndGet() because it will later be accessed without locking the
mutex.
Before the thread exits, it must call
threadCleanup() to release the entry in readers_states and assigned_threads, so that other newly created threads may use it:
public void threadCleanup() {
mutex.lock();
assigned_threads[tid.get()] = -1;
//
Search the highest non-occupied entry and set the num_assigned to it
for (int i = MAX_NUM_THREADS-1; i > 0; i--) {
if (assigned_threads[i] != -1) {
num_assigned.set(i+1);
break;
}
}
mutex.unlock();
}
A non obvious optimization is in use here: we search from the
last to the
first element of the
assigned_threads to find the highest of the
free entries, but when we allocate in
threadInit() we search from the
first to the last for the first available entry. That I know of, there is no easy way to improve this and still be able to use
num_assigned as the maximum entry that needs to be searched for. See the scanning loop in writeLock() to understand the reason behind doing this.
Read Lock
This is where things start to get interesting, we are going to look at the read-only locking mechanism.
We start by setting the entry in readers_states to
RSTATE_PREP. This will indicate to a possible writer that this thread is about to start a Read operation, or that it will see that a Writer is about to start and wait for it. If the Writer has started, or wishes to do so, then write_state will be 1, and this Reader will move to
RSTATE_WAITING and
yield() until
writer_state is in
WSTATE_WRITEORWAIT
public void readLock() {
int local_tid = tid.get()*CACHE_PADD;
readers_states.set(local_tid, RSTATE_PREP);
if (writer_state.get() > 0) {
// There is a Writer waiting or working, we
must yield()
while (writer_state.get() > 0) {
readers_states.set(local_tid, RSTATE_WAITING);
while(writer_state.get() > 0)
Thread.yield();
readers_states.set(local_tid, RSTATE_PREP);
}
}
//
Read-Lock obtained
readers_states.set(local_tid, RSTATE_READING);
}
Unlocking is just a matter of setting the current Reader's state back to
RSTATE_UNUSED which is done with .set() but could even be done with .lazySet(), but delaying it might keep a Writer on hold.
public void readUnlock() {
int local_tid = tid.get()*CACHE_PADD;
readers_states.set(local_tid, RSTATE_UNUSED);
}
Write Lock
TODO

{kind=link}